캐시
- 가져오는데 비용이 드는 데이터를 한번 가져온 뒤에는 임시로 저장
- 프록시는 웹서버와 클라이언트 사이에 들어가서 웹서버에 대한 액세스 동작을 중개하는 역할을 하는데, 액세스 동작을 중개할 때 웹서버에서 받은 데이터를 디스크에 저장해두고 웹서버를 대신하여 데이터를 클라이언트에 반송하는 기능을 가진다
캐시 서버 사용
- 데이터베이스 서버와 웹서버같은 역할에 따라 서버를 나누는 방법, 역할별 분산 처리 방법 중 하나이다
- 프록시라는 구조를 사용하여 데이터를 캐시에 저장하는 서버이다
- 캐시 서버는 웹 서버에서 받아 보존해 둔 데이터를 읽어서 클라이언트에 송신만해서 웹서버 보다 빨리 데이터를 송신한다
- 사용자가 캐시서버에 HTTP의 리퀘스트르 메시지를 보낸다. 캐시서버는 리퀘스트 메시지의 내용을 조사하고 데이터가 자신의 캐시에 저장되었는지 조사한다.
캐시 종류
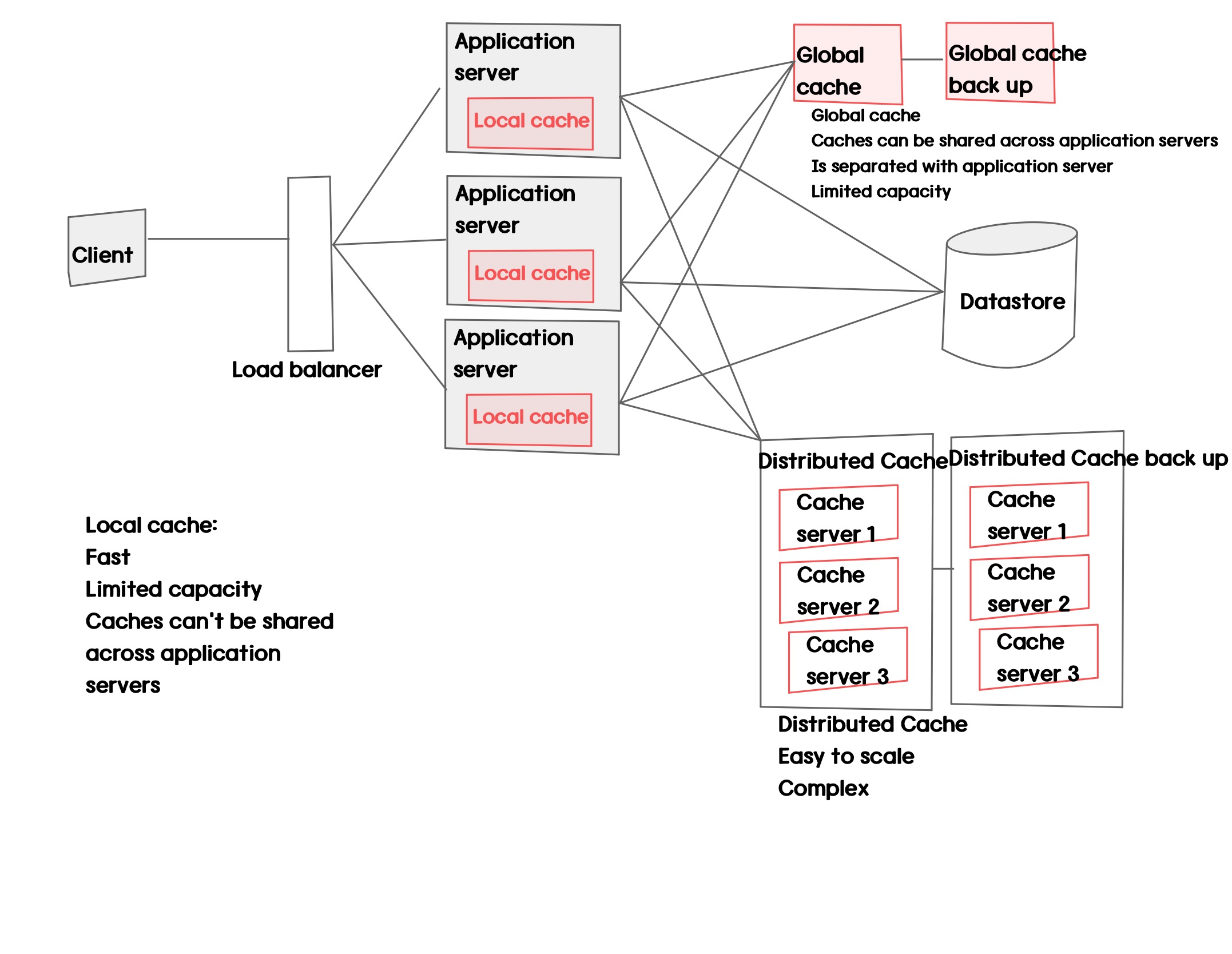
로컬캐시
글로벌 캐시
분산된 글로벌 캐시
로컬캐시가 해당 서버 메모리에 요청하는 것이라 더 빠른데도 리모트 캐시를 쓰는 이유 ?
- 데이터 정합성 때문.
- 로컬 캐시는 각 서버별로 존재해 서버별로 캐시를 공유할 수 없음
- 한 서버내의 로컬캐시의 데이터가 변경되었을때 다른 서버의 로컬캐시에서 기존내용을 가지고올 수 있음
- 로컬캐시는 모든 유저에게 동일한 내용을 주로 담는다
리모트 캐시 과정
크게 redis에서 찾기 -> 없으면 DB에서 조회 -> redis넣어서 조회 / 있으면 바로 redis에서 조회
- 1번 서버에서 Redis에 user : hailey가 있는지 확인
- 없으면 DB에서 조회 후 Redis에 적재
- 2번 서버(다른서버)에서 Redis에 user : hailey가 있는지 확인
- Redis에 있으면 response
- 1번 서버와 2번서버 모두 동일한 데이터 리턴
- 데이터 user : hailey의 전화번호 변경
- DB 업데이트
- Redis 캐시에 해당 데이터를 찾아 삭제 (Evict) -> Redis에 해당 데이터 없음
- 없으면 DB에서 조회(새로운 데이터) 후 Redis에 적재
쿠키
네이버 로그인 해제 : 세션아이디가 쿠키 보관함에서 삭제
로그인창의 아이디를 자동완성
공지메시지 하루 안보임
로그인안한 상태로 장바구니이용
사용자의 편의를 위하되 지워지거나 조작되거나 가로채이더라도 큰 일 없을 정보들을 브라우저에 저장
세션
사용자나 다른 누군가에게 노출되어서는 안되는 서비스 제공자가 직접 관리해야하는 내용
메모리 계층 구조
데이터를 저장하는 공간의 속도와 용량은 반비례 관계
- 속도가 빠른 메모리일 수록 용량이 작음
- 용량이 큰 저장장치는 속도가 느림
- 둘다 잡기에는 비용이 너무 많이 든다
- 그래서 데이터 저장 공간은 속도와 용량에 따라 특성에 맞게 역할을 나누어서 사용
'* > What I did today' 카테고리의 다른 글
| GC (0) | 2023.01.01 |
|---|---|
| static 변수는 JVM의 어디에 저장될까 ? (0) | 2022.12.25 |
| JVM (0) | 2022.12.24 |
| Java - static 사용의 지양 (0) | 2022.12.17 |
| 서버가 죽는 이유 ,message queue (0) | 2022.07.20 |
| AWS Certified Cloud Practitioner - 합격 후기, 참고자료 정리 (5) | 2021.12.14 |
| 11/5 (함께자라기) (1) | 2021.11.06 |
| 11/03 (0) | 2021.11.03 |