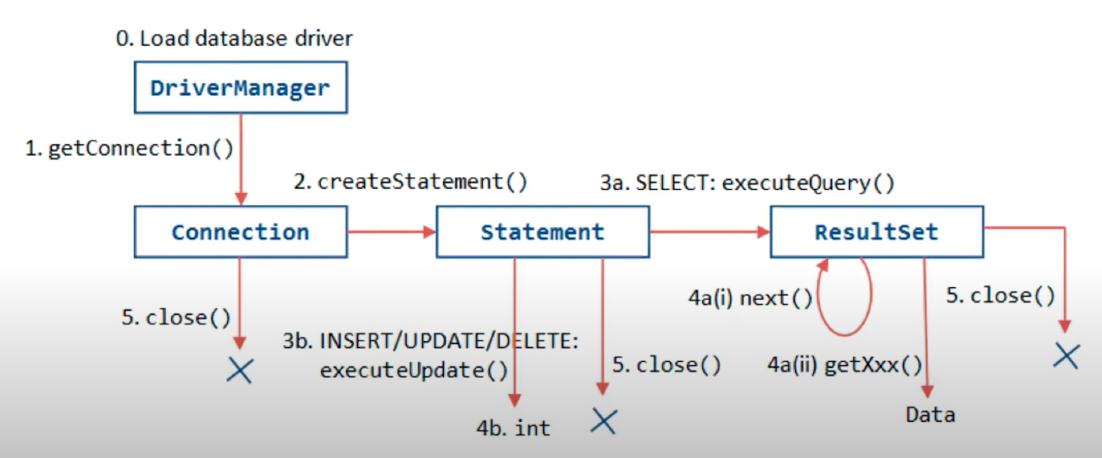
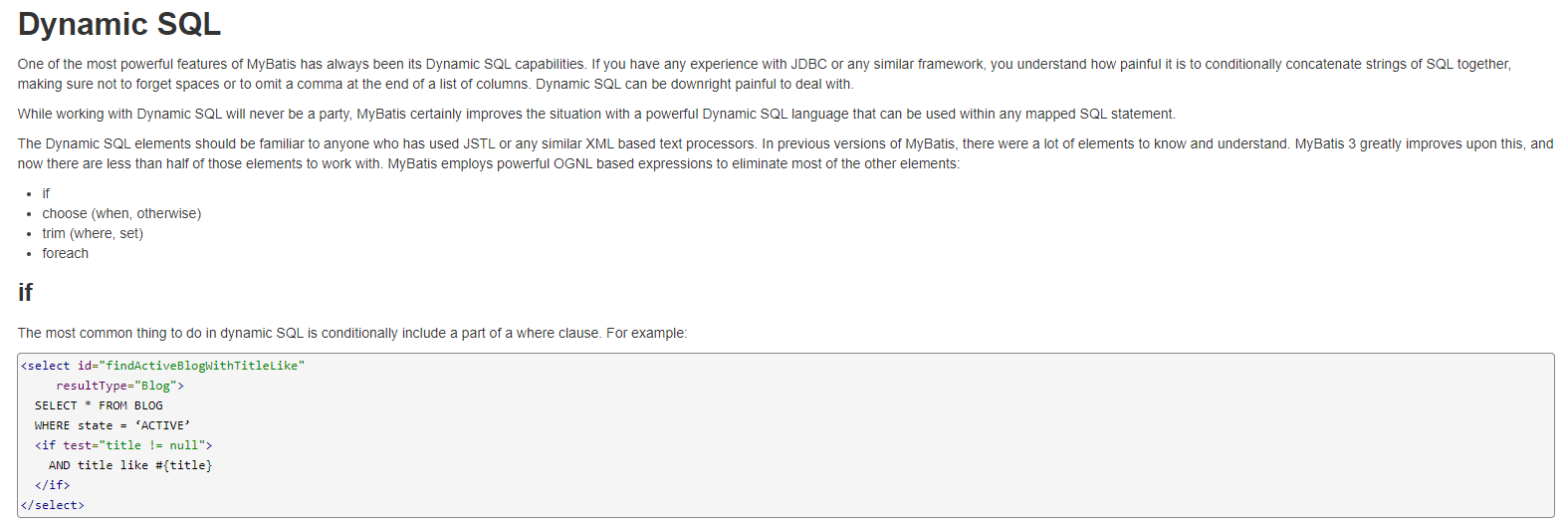
회사에서도 직렬화/ 역직렬화를 위해 사용하는 jackson 라이브러리.
마침 넥텝 과제하던 중 알게된 어노테이션 @Jacksonized를 정리해본다.
Jackson 라이브러리란 ?
spring-boot-starter-web 의존성을 주입하면 자동으로 이 라이브러리가 포함된다.
JSON 컨버팅할때 jackson을 사용하게된다.
@Jacksonized
역직렬화를 위한 어노테이션이다.
불변성을 보장하면서 역직렬화를 가능하게 한다.
@Jacksonized 어노테이션은 @Builder 또는 @SuperBuilder와 함께 사용한다.
이 어노테이션은 생성된 빌더 클래스를 Jackson의 역직렬화에 사용할 수 있도록 자동으로 구성합니다.
@Builder 또는 @SuperBuilde가 적용된 상황에서만 가능하다.
빌더의 동작을 변경하지 않는다.
@Jacksonized @Builder
@JsonIgnoreProperties(ignoreUnknown = true)
public class JacksonExample {
private List<Foo> foos;
}예시 코드
@Getter
@Builder
@Jacksonized
class JacksonExample {
private final String name;
private final int age;
}
class JacksonExampleTest {
@Test
void testJacksonSerializationAndDeserialization() throws IOException {
// 객체 생성
JacksonExample example = JacksonExample.builder()
.name("Bob")
.age(25)
.build();
// ObjectMapper를 사용하여 객체를 JSON 문자열로 직렬화
ObjectMapper objectMapper = new ObjectMapper();
String json = objectMapper.writeValueAsString(example);
// JSON 문자열을 사용하여 객체를 역직렬화
JacksonExample deserializedExample = objectMapper.readValue(json, JacksonExample.class);
// 값 비교
assertEquals("Bob", deserializedExample.getName());
assertEquals(25, deserializedExample.getAge());
}
}- JackonExample 클래스에 @Jacksonized 어노테이션을 적용했다.
- Jackson 의 직렬화 및 역직렬화에 사용되는 빌더 클래스를 자동으로 구성한다.
- 위 테스트 코드에서 객체를 생성하고 ObjectMapper를 사용하여 해당 객체를 json문자열로 직렬화 한후 다시 역직렬화한다.
- 역직렬화된 객체의 값과 원래의 값이 일치하는지 확인한다.
플젝 적용
아래는 넥텝 과제에 적용한 내 코드 일부분이다.
package cart.dto;
import cart.domain.Cart;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.extern.jackson.Jacksonized;
@Getter
@AllArgsConstructor
@Jacksonized
@Builder
public class CartCreateDto {
private final Long productId;
private final int count;
public Cart toEntity(Long memberId) {
return Cart.builder()
.productId(getProductId())
.memberId(memberId)
.count(getCount())
.build();
}
}- @Jacksonized 어노테이션을 사용해서 CartCreateDto 클래스가 Jackson과 함께 동작한다.
- Jacksonized 어노테이션과 Builder 어노테이션을 같이 사용해 빌더 패턴이 생성된다.
- 위 클래스의 객체를 Json 형식으로 직렬화해서 요청 바디에 넣는 테스트 코드를 작성하여 직렬화를 처리한다.
@DisplayName("로그인한 유저의 장바구니에 상품을 추가한다.")
@Test
void addItemToCart() {
CartCreateDto createDto = CartCreateDto.builder()
.productId(1L)
.count(1)
.build();
var result = given()
.auth().preemptive().basic(member.getEmail(), member.getPassword())
.contentType(MediaType.APPLICATION_JSON_VALUE)
.accept(MediaType.APPLICATION_JSON_VALUE)
.body(createDto)
.when().post("/carts/add-to-cart")
.then().log().all()
.extract();
assertThat(cartService.cartProducts(member).size()).isEqualTo(2);
assertThat(result.statusCode()).isEqualTo(HttpStatus.OK.value());
}- 요청을 보낼때 createDto 객체가 요청 바디에 담겨 전송된다.
- 서버에서 json 바디를 역직렬화하여 cartCreateDto 객체로 변환한다.
참고
https://www.baeldung.com/java-jackson-deserialization-lombok
'* > What I did today' 카테고리의 다른 글
| 객체지향 (0) | 2023.03.23 |
|---|---|
| How to Achieve More (3) | 2023.03.14 |
| DB Connection Pool (0) | 2023.02.15 |
| Tree (0) | 2023.01.10 |
| null 대신 Optional 클래스 (0) | 2023.01.02 |
| GC (0) | 2023.01.01 |
| static 변수는 JVM의 어디에 저장될까 ? (0) | 2022.12.25 |
| JVM (0) | 2022.12.24 |